Pigeon Farming Behavior Monitoring and Analysis
Project Leaders
Jiefeng Xie
Nuoer Long
Chengpeng Xiong

Project Leaders
Jiefeng Xie
Nuoer Long
Chengpeng Xiong
Project Example
Pigeon breeding behavior monitoring
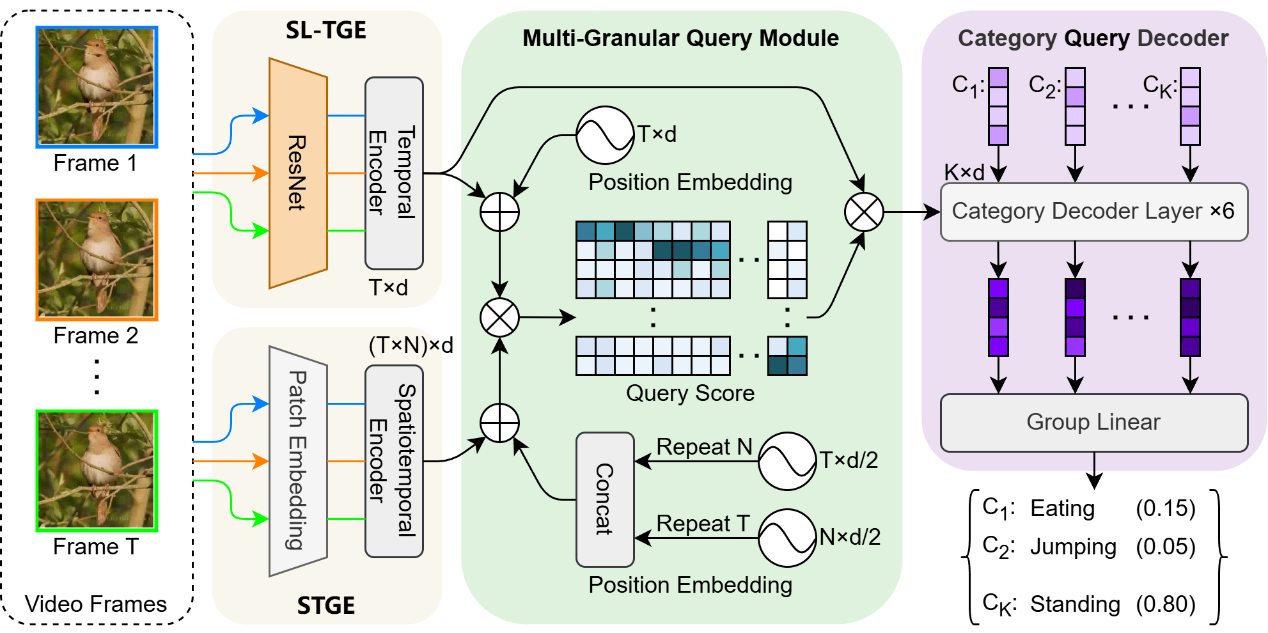
Project Example
Query-based multi-granularity behavior recognition network architecture

Project Example
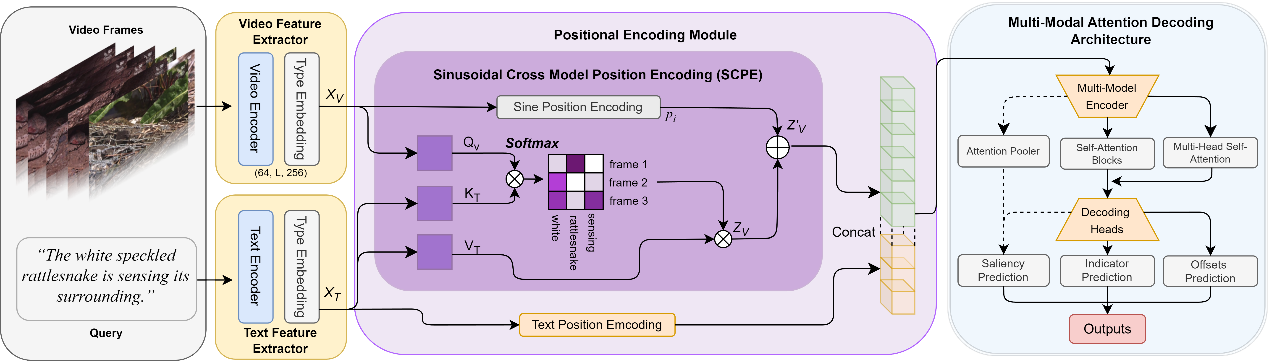
SCPE network architecture
Award

ICME Grand Challenge 2024 First Place